Model selection#
Perhaps we do not know the number of segments in a rating or that a power law is better than another type of model. In these situations, we want to compare the performance of one model against another, then select whichever models gives the best fit for the data. More specifically, we want to know the generalization performance of each model, which refers to their performance on new (out-of-sample) data.
One way to estimate generalization performance is cross validation, but it can be costly. In cross validation, a portion of the data is held out. If you don’t have a lot of data to begin with, holding out a portion can substantially degrade model fit.
An alternative approach is to use information criteria, which are measures that use in-sample data to estimate out-of-sample performance.
In this tutorial, we demonstrate how to select the number of segments in the Green River rating. We fit the rating with 1, 2, 3, and 4 segments, then use information criteria to select the number of segments that gives the best fit.
## Load the data
from ratingcurve import data
%load_ext autoreload
%autoreload 2
%xmode minimal
#suppress warnings and errors
import pymc as pm
import arviz as az
from ratingcurve.ratings import PowerLawRating
from ratingcurve import data
df = data.load('green channel')
Exception reporting mode: Minimal
WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
Fit the data#
Fit the data to ratings with 1 to 4 segments.
%%capture
# Output supressed, this will print "Finished" after running each of the four models
segments = [1, 2, 3, 4]
traces = []
for segment in segments:
powerrating = PowerLawRating(segments=segment,
prior={'distribution':'uniform'})
trace = powerrating.fit(q=df['q'],
h=df['stage'],
q_sigma=df['q_sigma'],
n=100_000)
traces.append(pm.compute_log_likelihood(trace, model=powerrating.model)) # Add arg to compute log likelihood
Convergence achieved at 46800
Interrupted at 46,799 [46%]: Average Loss = 85.956
Sampling: [a, b, hs_, model_q, sigma]
Sampling: [model_q]
Finished [100%]: Average Loss = -52.099
Sampling: [a, b, hs_, model_q, sigma]
Sampling: [model_q]
Finished [100%]: Average Loss = -48.863
Sampling: [a, b, hs_, model_q, sigma]
Sampling: [model_q]
Finished [100%]: Average Loss = -45.144
Sampling: [a, b, hs_, model_q, sigma]
Sampling: [model_q]
Now use arviz.compare to format the output.
# this model will generate warnings about the LOO
import warnings; warnings.filterwarnings('ignore')
compare_dict = {f'{i} segment': traces[i-1] for i in segments}
az.compare(compare_dict, ic='LOO')
| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| 2 segment | 0 | 70.349657 | 8.549018 | 0.000000 | 0.726856 | 5.137408 | 0.000000 | True | log |
| 3 segment | 1 | 65.855328 | 13.864734 | 4.494329 | 0.225427 | 8.260919 | 5.439832 | True | log |
| 4 segment | 2 | 61.405451 | 18.101380 | 8.944206 | 0.000000 | 11.568203 | 8.712622 | True | log |
| 1 segment | 3 | 54.114522 | 3.733332 | 16.235136 | 0.047717 | 3.279669 | 5.916546 | False | log |
As expected, the 2-segment model ranked highest.
Residual analysis#
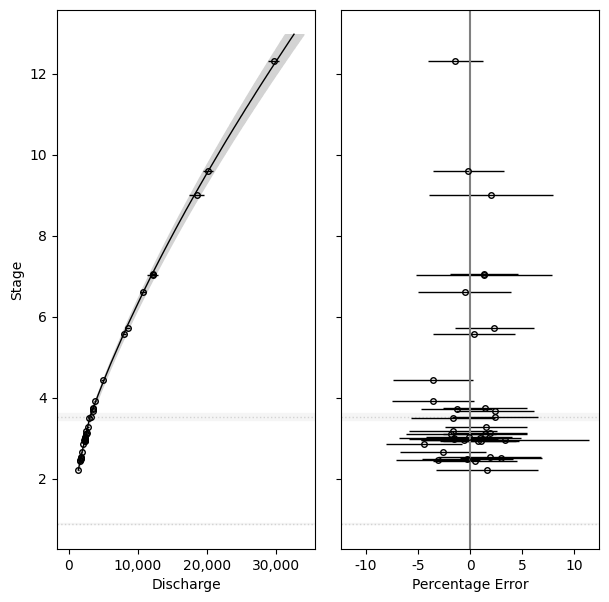
In practice, it can be helpful to plot to rating error (the deviations between the rating fit and the discharge observations). Here is a demonstration of how.
segments = 2
powerrating = PowerLawRating(segments=2,
prior={'distribution':'uniform'})
trace = powerrating.fit(q=df['q'],
h=df['stage'],
q_sigma=df['q_sigma'])
Convergence achieved at 162300
Interrupted at 162,299 [81%]: Average Loss = -15.995
Sampling: [a, b, hs_, model_q, sigma]
Sampling: [model_q]
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(7,7), sharey=True)
powerrating.plot(ax[0])
powerrating.plot_residuals(ax[1])
plt.subplots_adjust(wspace=0.1)
ax[1].set_ylabel('')
Sampling: [model_q]
Sampling: [model_q]
Text(0, 0.5, '')
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,xarray
Last updated: Mon Jun 03 2024
Python implementation: CPython
Python version : 3.11.9
IPython version : 8.25.0
pytensor: 2.22.1
xarray : 2024.5.0
arviz : 0.18.0
matplotlib : 3.9.0
ratingcurve: 0.1.dev1+g54c5899
pymc : 5.15.1
Watermark: 2.4.3